Du ved garanteret at Youtube er god til at finde nye videoer der passer til dig. Hvis du kan lide at se My little pony-videoer, kan du måske også lide at se dukkevideoer – og reklamer for My little ponies og dukker. Og hvis du kan lide at se gamer-youtubere, er der måske også andre gamere, du vil synes om – og samtidig er du måske interesseret i en annonce om et nyt computerspil?
På den måde er du også et produkt for YouTube, for de kan tjene mange penge hos en spilproducent ved at sørge for, at du ser deres video. Og spilproducenten tjener penge på, at du plager dine forældre om at få spillet, som du har set på YouTube, i fødselsdagsgave.
Det skyldes Machine Learning – eller maskinlæring – som er en ny teknologi, der allerede nu er en del af din hverdag. Nogle kalder også maskinlæring for kunstig intelligens eller AI (artificial intelligence). Din smartphone er fyldt med apps, og mange af disse bruger også maskinlæring.
Men maskinlæring kan også gøre en masse godt. For eksempel findes der en app, som kan vurdere et billede af et modermærke og forudsige, om det er hudkræft. Maskinlæring kan også hjælpe med at sortere flasker i flaskeautomater ved hjælp af stregkoden og formen af flasken.
Det seneste år er særligt AI, der ’selv’ skaber tekst og billeder, kommet frem. De mest populære er sprogbaserede AIs som ChatGPT eller SkoleGPT, der kan bruges til for eksempel brainstorm – og DALL-E, der kan lave billeder ud fra en beskrivelse. I BioNice skal du som medarbejder i Udviklingsafdelingen blandt andet selv prøve at udtænke en model, hvor du bruger maskinlæring til at løse og diskutere en problematik.
Hvad betyder maskinlæring? Hvad er en kunstig intelligens? Læs teksten i boksen nedenfor, og prøv at finde nogle hjemmesider, der beskriver begreberne. Skriv stikord ned på et stykke papir. Husk at gemme links til, hvor I fandt informationerne.
| Kunstig intelligens (KI, Artificial Intelligence, AI) er algoritmer, der gør det muligt for en computer at udføre en opgave på en måde, der kan virke intelligent. Det betyder, at programmet ’ser’ noget, det aldrig har set før, og derudfra kan det tage en beslutning. Det kan programmet ’lære’ med logiske regler (fx “hvis trafiklyset er grønt, må du gå over”), det kan bruge træningsdata (maskinlæring), eller det kan kombinere disse. Det kan for eksempel være en robot, der kan ’genkende’ en cykel fra en bil eller dig og dine klassekammerater. Det kan også være en chatbot, der kan svare på spørgsmål. Maskinlæring (ML) er et værktøj til at lave en kunstig intelligens ved hjælp af data. Maskinen ’lærer’ ved, at man for eksempel træner den med en hel masse billeder, som man giver forskellige kategorier, og derudfra kan den selv kategorisere nye billeder. Lidt ligesom du ved, hvordan en cykel ser ud ved at have set en masse cykler. En sådan ’maskine’ kaldes også en maskinlæringsmodel. For at det skal være AI, skal der dog ske en handling på baggrund af den opnåede viden. Neuralt netværk er en slags maskinlæringsmodel, som er rigtig god til mønstergenkendelse i for eksempel at kategorisere billeder og lyde. Den er opbygget af flere lag kunstige neuroner, hvor man har forsøgt at efterligne menneskehjernen. På den måde lagrer det neurale netværk viden om, hvad det har lært i neuronerne. Det er den slags maskinlæring som programmet Machine Learning for Kids bruger. Og det skal I arbejde med. Træningsdata er det data, som man fodrer maskinlæringsalgoritmen med. Man siger, at man træner modellen. Du kender måske bedst data som tabeller med tal i. Men det kan også være for eksempel tekst, billeder eller lyde. I øvelserne i dette forløb skal I arbejde med at træne neurale netværk med billeder. Bias eller forudindtagethed af data er, når data (som fx billeder) eller de kategorier, I har valgt, ikke helt afspejler virkeligheden, men er jeres valg. Alle de modeller, I laver, vil have bias, da det jo netop er jer, der vælger data. Hvis nu I skal kategorisere biler og cykler, men kun har taget billeder af cykler med grønt i baggrunden og biler med asfalt i baggrunden, vil algoritmen have svært ved at genkende kende en cykel på noget asfalt. Eller hvis I har taget 97 billeder af cykler og tre billeder af løbehjul, vil den til gengæld have meget svært ved at genkende et løbehjul. Data og AI-modellerne vil altid være biased, men man kan gøre mange ting for at undgå, at det bliver et problem. Bias i data er en af de største udfordringer i maskinlæring og kunstig intelligens, men er også en forudsætning for, at programmerne virker godt. For hvis nu vi ikke er interesserede i løbehjul, er det fint at algoritmen ikke er særlig god til at genkende dem, og ikke har fået fyldt hukommelsen op med løbehjul. |
1. Lær værktøjet at kende
- Gå ind på Machine Learning for Kids. Brug koden, dit team har fået fra jeres afdelingsleder, til at logge ind.
- Gå ind på Projects og tryk “Add a new project”.
- Vælg et projektnavn, for eksempel “Like”. Ved Project Type skal I vælge “recognising images”. Ved Storage skal I vælge ”In your web browser”. Tryk til sidst ”Create”.
- Klik på jeres projekt og dernæst “Train”.
- Tilføj ”Add new label” for hver kategori, der skal genkendes, f.eks. “Thumbs up” og “Thumbs down”.
- Tag eller find mindst 5 billeder af thumbs up og 5 billeder af thumbs down, og upload dem. I kan også drag ’n droppe billeder fra internettet – husk dog at tjekke, om I må bruge billederne. Der skal være lige mange billeder i hver kategori.
- Når I tager eller finder billederne, må der ikke komme for meget baggrund med, og man må ikke kunne se jeres ansigter. Tag billederne fra forskellige vinkler. I kan også tegne thumbs up og thumbs down.
- Når det er gjort, skal I gå tilbage til projektsiden, trykke på “Learn & Test” og derefter trykke på “Train new machine learning model”. Dette kan tage op til 5-10 minutter.
- I skyen bliver der trænet en maskinlæringsmodel, som kan “genkende” billeder ud fra de eksempler, I har givet. Modellen svarer med en label, dvs. programmet fortæller jer, om det genkender billedet som thumbs up eller thumbs down.
- I tester, om jeres model virker, ved at tage et billede, enten med thumbs up eller thumbs down, og trykke på ”Test”. Jeres model svarer nu, hvad den har genkendt billedet som, og hvor sikker den er i procent.

2. Prøv at lave andre projekter
Lav et nyt projekt med samme fremgangsmåde, hvor I selv finder på, hvad I vil få programmet til at skelne mellem. Det kan fx være cykler overfor løbehjul eller flasker overfor pap.- Gå ind på Machine Learning for Kids. Brug koden dit team har fået fra afdelingslederen til at logge ind.
- Gå ind på Projects og tryk “Add a new project”.
- Navngiv projektet ”Mad”, og ved Project Type skal I vælge “recognising images”. Ved Storage skal I vælge ”In your web browser”. Tryk til sidst ”Create”.
- Klik på jeres projekt og dernæst “Train”.
- Tilføj ”Add new label” for hver kategori, der skal genkendes. I skal lave 3 labels: Sund, Mellem og Usund.
- Tag eller find mindst 5 billeder til hver label og upload dem. I kan også drag ’n droppe billeder fra internettet. Der skal være lige mange billeder i hver kategori. Når I tager eller finder billederne, må der ikke komme for meget baggrund med, og man må ikke kunne se jeres ansigter. Tag billederne fra forskellige vinkler. I kan også tegne motiver.
- Når det er gjort, skal I gå tilbage til projektsiden og trykke på “Learn & Test” og derefter på “Train new machine learning model”. Dette kan tage op til 5-10 minutter.
- I skyen bliver der trænet en Machine Learning-model, som kan genkende billeder ud fra de eksempler, I har givet. Modellen svarer med en label, dvs. programmet vil fortælle jer, om det genkender billedet som sund, mellem eller usund.
- I tester, om jeres model virker, ved at tage et billede af noget mad og trykke på ”Test”. Jeres model vil nu svare, hvad den har genkendt billedet som, og hvor sikker den er i procent.


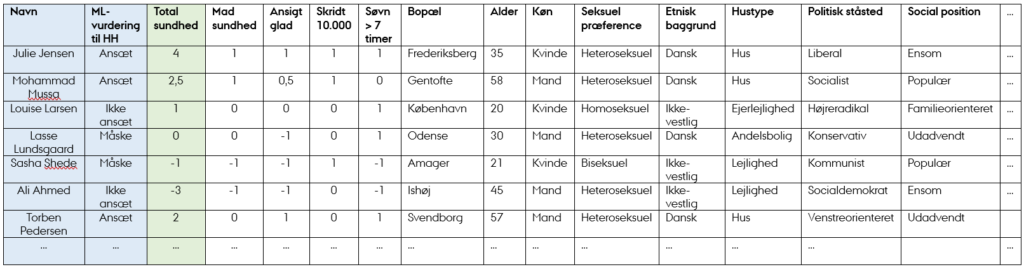
Artikel: Sundhedsapps vinder frem blandt danskerne
- Mere end halvdelen af danskerne har over de sidste seks måneder anvendt sundhedsapps, der måler deres fysiske aktivitet. Også brugen af apps, der måler eller registrerer sundhedstilstande som puls, blodtryk eller menstruationscyklus, er i støt stigning, og tallet vil kun vokse i fremtiden.
- Mere end hver anden dansker, 55 pct., har inden for de seneste seks måneder brugt en sundhedsapp, der måler deres fysiske aktivitet.
- Cirka hver tredje dansker forventer at bruge denne slags apps i de kommende år. Potentialet er dog størst blandt de ældre, da dobbelt så mange danskere over 50 år forventer at bruge sådanne apps i fremtiden.
Læs mere: Ny undersøgelse: Sundhedsapps vinder frem blandt danskerne – Dansk Erhverv
Artikel: Selvmonitorering skal være frivilligt og anonymt
- Det er positivt, at virksomheder er interesserede i medarbejdernes trivsel og velfærd, men de bør ikke bruge selvmonitorering som led i en vurdering af ansatte. Tilbuddet skal være frivilligt.
- Det er afgørende, at oplysningerne bliver opsamlet og opbevaret i anonymiseret form, så virksomhederne kan holde øje med den generelle trivsel på arbejdspladsen, mens det kun er den enkelte medarbejder, der kan følge de personlige sundhedsdata.
- Det er vigtigt at være opmærksom på teknologiens begrænsninger i forhold til at sikre et godt arbejdsmiljø.
Læs mere: Selvmonitorering skal være frivilligt og anonymt – Djøfbladet
Artikel: Ny rapport om dataindsamling på arbejdspladsen: Lederne er positivt stemte for dataindsamling
- Den teknologiske udvikling giver uanede muligheder for at indsamle medarbejderdata og således blive klogere på bl.a. trivsel og effektiviseringsmuligheder.
- Nøglen til dataindsamling på arbejdspladsen er gennemsigtighed og åben dialog. 79 pct. af de adspurgte ledere i en undersøgelse angiver, at de anvender medarbejderdata indsamlet via digitale værktøjer i deres ledelsespraksis, og tæt på halvdelen af lederne er positivt stemt for dataindsamling.
- Data er vores tids olie, og det er derfor en naturlig og vigtig del af udviklingen, at arbejdspladser i stigende grad bruger medarbejderdata til at blive klogere på deres medarbejdere og arbejdsprocesser.
- De ledere, som er meget positivt stemte, anvender i højere grad medarbejderdata i deres ledelsespraksis og er ansat på en arbejdsplads med politik eller retningslinjer for indsamling og brug af data.
Artikel: Platformes dataindsamling bekymrer danskerne
- Tre ud af fire er bekymrede for, hvordan platforme indsamler og bruger persondata, når de handler på internettet.
- Platforme indsamler både data, når platformen bruges, men også når der bruges andre sider eller apps på samme device.
- Platforme får adgang til oplysninger om udseende, tanker, helbred, præferencer, netværk og købemønstre.
- Det er især til fordel for platformene i forhold til konkurrence.
Læs mere: Platformes dataindsamling bekymrer danskerne – forbrugdk
Artikel: Ny undersøgelse: Over halvdelen af ledere og medarbejdere ser en risiko for, at indsamling og anvendelse af medarbejderdata skader relationen
- Tilliden mellem leder og medarbejder er på spil, når der indsamles data om medarbejdere på arbejdspladsen.
- Digital dataindsamling på arbejdspladsen kan skade forholdet mellem leder og medarbejder.
- Der er overvejende skepsis over for indsamling af medarbejderdata. Hver femte medarbejder føler sig overvåget på grund af dataindsamling.
- Selvom et flertal på 46 procent af lederne er positivt stemt over for brugen af medarbejderdata, er et stort mindretal på 38 procent samtidig skeptiske.
- Lederne er samlet set klart mere positive end medarbejderne.
Artikel: Befolkningsundersøgelse: Digital dataindsamling på arbejdspladsen
- Der er en bekymring for øget digitalisering, hvor ledere bruger digitale værktøjer, der indsamler data om ansatte, og som kan bruges til at måle og kontrollere medarbejderens effektivitet og værdi for arbejdspladsen.
- De fleste medarbejdere oplever, at der bliver indsamlet data om dem på arbejdspladsen, men få er positivt stemte.
- Medarbejdere, der har følt sig overvåget, oplever i højere grad, at deres leder har lav eller mellem tillid til dem.
- Danskerne bakker i højere grad op om indsamling af data om kriminelle handlinger end om fysisk sundhed.
- Kun én ud af fire medarbejdere er helt sikre på, at de har kendskab til de regler, der regulerer arbejdspladsers indhentning af medarbejderdata.
- Over halvdelen af danske medarbejdere er bekymrede for, at indsamling af data skader forholdet mellem leder og medarbejder.
Læs mere: Medarbejderdata på arbejdspladsen – Algoritmer, Data og Demokrati